
悩める人「今、巷でプログラミングが流行っているけど、pythonを使ってPDFをうまく操作できないかな。。。」
こんな方に向けた記事です。
結論、今回紹介する4つのPDF便利技はこちらです。
pythonを用いたPDF便利技4選
・PDFからテキストを抽出する。
・新しいPDFを作成する。
・PDFのページを回転する。
・PDFのページを重ね合わせる。

私は今、外科の後期研修医をしています。
外科医として習練する傍ら、機械学習を用いた臨床研究などを行っています。
今、医療業界ではプログラミング、AIに大きな関心が集まっており、AI関連の研究発表が多数なされています。
・大腸がんのマイクロサテライト不安定性を予測する機械学習アルゴリズム構築(Lancet Oncology)
また、医療業界だけでなく製造業、金融など様々な業界でプログラミングに注目が集まっています。
・医師が処方する保険適用「ニコチン依存症治療アプリ」など研修開発のCureAppが21億円調達
小学校ではプログラミング学習が必修化する(文部科学省ホームページ)などこれからの社会では英語や数学のように当たり前にプログラミング技術が必要とされる時代が迫っています。
今後、どの領域であれ、最低限のプログラム知識は必須になることが確実だと思います。
そんな中、少しでも皆様の力になれば、とプログラミングに関する知識を発信しています。
今回は、pythonとPDFに関する非常に基本的な技術を4つ紹介します。
どれもすぐ自分で手を動かして実践できるものです。是非最後までご覧ください。
また今回の記事は退屈なことはPythonにやらせよう ―ノンプログラマーにもできる自動化処理プログラミングを参考にしています。
pythonを利用した日々の業務の効率化について非常に分かりやすく書かれていますので興味のある方はリンクより是非ご覧ください。
目次
pythonで出来るPDF便利技4選

今回の作業環境はGoogle Colaboratoryを利用します。
PDFからテキストを抽出する
PythonでPDFからテキストを抽出するには主に以下の3つのライブラリが利用されています。
ポイント
ライブラリ毎に見ていきましょう。
PyPDF2
まず自分のパソコン中にテキスト抽出したいPDFを準備しましょう。
今回はword fileをPDF化したサンプルを用意しました。(sample1)
早速コードを書いていきます。
まずは自分のパソコン内のファイルをGoogle colaboratoryへインポートします。
from google.colab import files uploaded=files.upload()
すると以下のように表示されるためファイルを選択から今回テキスト抽出をしたいPDFを選択します。
次のように表示されればインポートが問題なく完了しています。

続いてPDF編集に必要なPyPDF2というライブラリをインストールします。
pip install PyPDF2

このように表示されればインストール完了です。 続いて実際にGoogle Colaboratory上で利用できるようにPyPDFのインポートを行います。
import PyPDF2
続いてPDFからテキストを読み取ります。少し難しい言葉で言うとバイナリファイルの読み込みを行います。
バイナリファイルとはテキスト以外で構成されたファイルであり、PDFもバイナリファイルに当たります。
pdf_file=open("sample1.pdf",mode="rb")
バイナリファイルの読み込みにはopen関数を用います。読み込みの際はopen関数のmodeをrbとします。
そして読み込んだsample1.pdfをpdf_fileと定義します。
pdf_read=PyPDF2.PdfFileReader(pdf_file)
PyPDF2によって読み込んだpdf_fileのテキストデータをpdf_readと定義します。
次に読み込んだsample1.pdf、つまりpdf_readのページ数を確認します。
pdf_read.numPages >>1
numPagesがページ数を確認するコードになります。今回は1枚で構成されるPDFなのでページ数は1となります。2枚で構成されるPDFであれば2、10枚で構成されるPDFであれば10となります。
次にPDF上の特定のページを限定して抽出します。
page_0=pdf_read.getPage(0)
今回はPDFファイルの最初のページを抽出しました。ページは0からカウントされるためページ0になります。
最後に指定したページのテキストを抽出します。
page_0.extractText()

完全ではありませんがこのようにテキストが抽出されます。

矢印のボタンからcopy valueを行い、ペーストすると、以下のようにきれな文章になります。
>>This site is mainly for medical professionals to share useful wisdom on career, programming, love and marriage. Thank you very much for reading this site and I look forward to your continued support.
今回利用したPyPDF2は日本語のテキストは抽出できません。また英語もフォントによっては抽出できないことがあります。
日本語の抽出を行う場合は、これから紹介するTika-python 、pdfminer.sixのどちらかを用いましょう。
Tika-python
次はTika-pythonを用いてPDFからのテキスト抽出を行います。
同じくGoogle colaboratoryを利用して行います。
今回は日本語のPDFサンプルを作成しました。(sample_japanese)
さっそくコードを書いていきます。
まずは先述のようにGoogle colaboratoryにPDFをインポートします。
from google.colab import files uploaded=files.upload()

続いてTikaの中のparserというPDFの文字抽出に必要なライブラリをインポートします。
from tika import parser
そしてPDFから文字の読み取りを行います。
pdf_read = parser.from_file("sample_japanese.pdf")
text = pdf_read["content"]
print(text)

まずparserでPDFの読み取りを行います。
そして["content"]によってテキストの読みとりを行い、読み取ったものをtextと定義します。
print(text)でtextの出力を行います。printに関しては【Python】print()の使い方の記事で使い方を紹介しています。
するとご覧の様にテキストが出力されます。
日本語でもテキスト抽出が可能でコードも単純なため非常に簡単にPDFからテキスト抽出を行うことができます。
pdfminer.six
次にpdfminer.sixを利用したPDFからのテキスト抽出を見てみます。
先ほどと同じsample_japaneseを使用します。
今回はGoogle colaboratoryにPDFインポートした後から見てみます。
まずはpdfminer.sixをインポートします。
pip install pdfminer.six

このような画面がでればインストール完了です。
from pdfminer.high_level import extract_text
次にpdfminerよりPDFからテキストを読み取るためのextract_textをインポートします。
text = extract_text('sample_japanese.pdf')
print(text)

extract_textでPDFのテキストを読み取り、読み取った内容をtextと定義します。
あとはそれをprintで出力するのみです。
pdfminerを利用した場合も非常にシンプルなコードで実装することができます。
新しいPDFを作成する
今回は用意した2つのPDFを結合した新しいPDFを作成します。
ライブラリはPyPDF2を利用します。
今回は2ページからなるPDF(sample_2pages)、画像を張り付けたPDF(sample_image)の2つを用意しました。
まずはPDFを読み込みます。
from google.colab import files uploaded=files.upload()
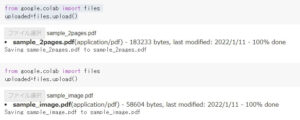
またPyPDF2をインポートします。
pip install PyPDF2
import PyPDF2
次に先述と同じようにバイナリファイルの読み込みを行います。
pdf1=open("sample_2pages.pdf", "rb")
pdf2=open("sample_image.pdf", "rb")
PyPDF2によって読み込んだpdfのテキストデータをそれぞれpdf_readと定義します。
pdf1_read=PyPDF2.PdfFileReader(pdf1) pdf2_read=PyPDF2.PdfFileReader(pdf2)
次にPyPDF2のPdfFileWriterを用いて新規のPDFを作成します。空のPDFを作成しそこへ既存のページを足していくイメージです。
pdf_writer=PyPDF2.PdfFileWriter()
次に先ほど作成したPDF1, POD2の各ページを空のpdf_writerへ足していきます。
for page_num in range(pdf1_read.numPages): page_obj=pdf1_read.getPage(page_num) pdf_writer.addPage(page_obj)
for page_num in range(pdf2_read.numPages): page_obj=pdf2_read.getPage(page_num) pdf_writer.addPage(page_obj)
for構文を用いて各PDFの各ページを読み込み、それを新たに作成したpdf_writerへ足しました。
pdf_output_file=open("pdf_combined.pdf", "wb")
pdf_writer.write(pdf_output_file)
pdf_output_file.close()
pdf1.close()
pdf2.close()
1行目で新たな空のpdfであるpdf_combined_fileを作成し、これをpdf_output_fileと名付けます。
そしてpdf_output_fileへこれまでに作成したpdf_writerを書き込みます。
これで新たなpdf_combinedの完成です。
元の2つのPDFが連結していることがわかります。
PDFのページを回転する
次はPDFのページを回転させるプログラムです。
今回もライブラリはPyPDF2を利用します。
まずPyPDF2を読み込みます。
import PyPDF2
今回は前回使用した画像を張り付けたPDF(sample_image)を引き続き利用します。
pdf_imageとして今回の使用するPDFを開き、pdf_readとして読み込みます。
pdf_image=open("sample_image.pdf","rb")
pdf_read=PyPDF2.PdfFileReader(pdf_image)
次に回転させるページをpage0として抽出します。
page0=pdf_read.getPage(0)
抽出したpage0を回転させます。今回は90度回転させます。
page0.rotateClockwise(90)
回転させたページをrotatedPage.pdfとして書き出します。
前述のPdfFileWriterを用います。
pdf_writer=PyPDF2.PdfFileWriter()
pdf_writer.addPage(page0)
pdf_rotated=open("rotatedPage.pdf","wb")
pdf_writer.write(pdf_rotated)
pdf_rotated.close()
すると90度回転したPDFが完成します。

数字を変えることであらゆる角度で回転させることができます。
PDFのページを重ね合わせる
前回も使用した2ページからなるPDF(sample_2pages)、画像を張り付けたPDF(sample_image)を利用します。
ライブラリは同じくPyPDF2を利用します。
前述と同じようにまずはそれぞれのファイルを開き、読み込みます。
pdf1=open("sample_2pages.pdf", "rb")
pdf2=open("sample_image.pdf", "rb")
pdf1_read=PyPDF2.PdfFileReader(pdf1) pdf2_read=PyPDF2.PdfFileReader(pdf2)
そして重ね合わせるページを抽出します。
今回は文字の書いているPDFの1枚目を抽出しもう1つの画像のページと重ね合わせます。
ページを重ね合わせるにはmergePageを用います。
pdf1_first_page=pdf1_read.getPage(0) pdf1_first_page.mergePage(pdf2_read.getPage(0))
そして前述と同じようにPdfFileWriterを用いて新しく作成したPDFに重ね合わせたページを足します。
pdf_writer=PyPDF2.PdfFileWriter()
pdf_writer.addPage(pdf1_first_page)
result_pdf_file=open("merged.pdf","wb")
pdf_writer.write(result_pdf_file)
result_pdf_file.close()

このようにページ同士が重ね合わさった新たなPDFを作ることができます。
さいごに
以上、pythonを用いたPDFの便利技を4つ紹介しました。
当サイトではプログラミングに関する知識を発信しています。
是非ご覧下さい。
この記事が少しでも皆様の助けになれば幸いです。




