
プログラミングを学ぶ人「機械学習の特徴量選択って何?」
こんな方に向けた記事です。
本記事ではPythonを用いたデータ分析で大切な特徴量選択と特徴量の重要度について解説していきます。
Pythonを用いたデータ分析では多くの特徴量が提示されることが多いです。
この特徴量の中にはモデルの精度に大きく寄与しないものもたくさんあります。
このような余計な特徴量が多く含まれてしまうとモデルの精度が落ちてしまうことがあります。
このような事態を防ぐために、特徴選択をすることでできるだけ有益な特徴量を残しながら余計な特徴量を取り除くことができます。
本記事の学習目標はこちらです。
本記事の学習目標
- 特徴量とは何か理解する
- 特徴選択の大きな3つの方法を理解する
- 特徴量の求め方を理解する
目次
機械学習の特徴量選択
特徴量とは文字通り特徴のことを指します。
例えば、心不全患者の予後予測モデルを作成する際、患者の喫煙歴、飲酒歴、既往歴などが特徴量にあたります。特徴量の中にはモデル、つまり心不全患者が死亡するか生存するかを予測する際にモデルの正確性に大きく寄与している因子もあればほとんど寄与していない因子もあります。
できるだけ有効な特徴量を残しながら特徴を減らすこと、これが特徴選択です。各特徴量がどのくらいモデルの正確性に寄与しているかが特徴量の重要度です。
3種類の特徴選択
特徴選択には大きくわけて3種類が存在します。
3種類の特徴選択
- 単変量統計を用いる手法
- 特徴量の重要度を用いる手法
- 反復して探求する手法
一つずつ見ていきましょう。
単変量統計を用いる手法
各特徴量と目的変数から何らかの統計量を計算しその統計量の順序で優れるものから特徴量を選択する手法です。
単変量統計はあくまである一つの特徴量と目的変数の1対1の関係に着目しているため特徴量同士の相互作用は考慮されません。
単変量統計を用いる手法には大きく分けて以下の2つの方法があります。
単変量統計を用いる2つの方法
- 相関係数を用いる
- カイ二乗統計量を用いる
相関係数を用いる
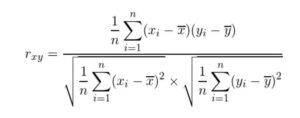
<引用>https://bellcurve.jp/statistics/course/9591.html
(x1,y1)、(x2,y2)、(x3,y3)、・・・、(xi,yi)・・・(xn,yn)の要素からなるデータとし、x-, y-はxの平均、yの平均とします。
分母はx,yのそれぞれの標準偏差の積、分子はx,yの共分散です。
各特徴量と目的関数の相関係数を算出し相関関数の絶対値の大きい方から特徴量を選択するのがこの手法です。
<参考>
カイ二乗統計量を用いる
カイ二乗統計量を算出し、統計量の大きい方から特徴量を選択する手法です。
注意点としてカイ二乗統計量を使用した手法を用いる時は特徴量は負ではない値で分類タスクである必要があります。また特徴量の値の大きさに影響されます。つまり特徴量の平均が10のものと1000のものでは統計量に影響がでてしまうということです。
<参考>
特徴量の重要度を用いる手法
モデルから出力される特徴量の重要度を用いて特徴選択を行う方法です。今回はランダムフォレストを用いる方法とGBDTを用いる方法の2つを紹介していきます。
ランダムフォレストの特徴量の重要度
ランダムフォレストによって特徴量の重要度を出力します。重要度は分岐前後の基準となる値(回帰では二乗誤差、分類ではジニ不順度)の減少によって計算されます。
重要度の高いものから特徴量を選択することでよりモデルの精度をあげることができます。
GBDTの特徴量の重要度
GBDTによって特徴量の重要度を出力します。GBDTのアルゴリズムの一つであるxgboostは以下の3つの種類の特徴量の重要度を出力することができます。
- ゲイン:その特徴量の分岐によってどのくらい目的関数が減少したか
- カバー:その特徴量によって分岐させられたデータの数
- 頻度:その特徴量が分岐に現れた回数
Pythonのデフォルトでは頻度が出力されますが、ゲインを出力するのが最も良いと思います。
結果から重要度の高いものから特徴量を選択することでよりモデルの精度を上げることが出来ます。
反復して探索する方法
シンプルに特徴量の組み合わせを変えて何度もモデルを作成し、精度の高いものを探索していく手法です。計算量が多くなることから用いられることは多くありません。
さいごに

今回は特徴量選択と特徴量の重要度について一緒に勉強しました。
今回紹介した中でも私は特徴量の重要度を用いる手法を最もおすすめします。
なぜなら可視化できるので非常に理解しやすく、データ分析のコンペなどでも用いる人が多いからです。
具体的な使い方やコードは実際のデータ解析をしている記事で御覧ください。
特徴量とは文字通り特徴のことを表し、モデルの正確性に寄与する特徴を残しながら影響の小さい特徴を取り除いていくことを特徴選択と言いました。
特徴選択にはこれらの3つの手法がありました。
- 単変量統計を用いる手法
- 特徴量の重要度を用いる手法
- 反復して探求する手法
そして単変量統計を用いる手法では今回この2つを紹介しました。
- 相関係数を用いる
- カイ二乗統計量を用いる
特徴量の重要度を用いる手法ではこの2つを紹介しました。
- ランダムフォレストを用いる
- GBDTを用いる
それぞれ概念自体の理解はとっつきにくいと思います。
具体例で実際にイメージしながらじっくりと理解していくのが良いと思います。
機械学習はプログラミング言語のPythonを用いれば、今持っている自分のパソコンですぐに実践することができます。
英語論文になっている手法もしっかりと勉強すれば、自分のパソコンで出来ます。
このサイトでは、プログラミングに興味のある医学生、医師のための情報を発信しております。
プログラミングの学習方法には大きく分けて、「独学」と「プログラミングスクール」の2つがあります。
当サイトでは一貫してプログラミングスクールを利用することをおすすめしています。
なぜなら、独学で勉強した私が非常に苦労したからです。
また私はプログラミングを学習するにあたり、師匠・メンターのような存在がいました。
わからないところは教えてもらっていました。
そのような環境でなければ0から独学で勉強するのはとても効率が悪いと思います。
詳しくは、プログラミングの独学は難しいです【私の失敗談】で紹介しています。
この記事が一人でも多くのプログラミングに興味のある方のお役に立てば幸いです。




