
プログラミングを学ぶ人「機械学習ってどんなことができるの?」
こんな方に向けた記事です。
本記事ではPythonを用いたデータ分析における3種類のタスクについて解説していきます。
データ分析ではまずその目的をはっきりとさせる必要があります。
Pythonのデータ分析では目的に応じて3種類のタスクが存在します。今自分はこのタスクに取り組んでいる、とデータ分析をしている最中に常に意識することで余計な時間をかけずに目的にたどり着くことができます。
本記事の学習目標
- データ分析の3つのタスクを理解する。
- タスクごとの評価指標を理解する。
【機械学習】タスクについてわかりやすく解説
Pythonデータ分析における3種類のタスクはこちらです。
3種類のタスク
- 回帰タスク
- 分類タスク
- レコメンデーション
基本的にはこの3種類に分類することができます。タスクはそれぞれ評価指標が異なります。
ひとつひとつ、どのようなものなのか、そして評価指標には何を用いるのか見て参りましょう。
評価指標に関しては、機械学習の評価指標についてわかりやすく解説でさらに詳しく紹介しています。
回帰タスク
株価、医療費、来院数など数値を予測するのが回帰タスクです。
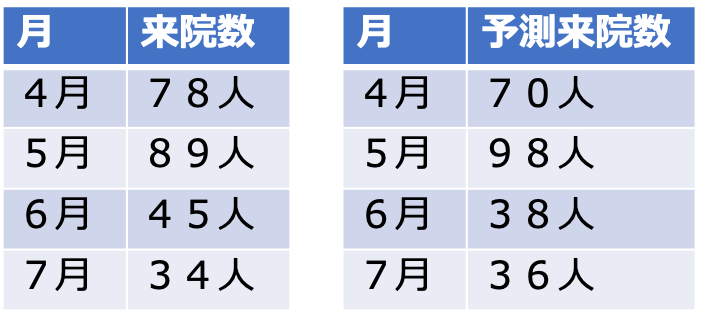
このように数値を予測するのが回帰タスクです。
評価指標としてRMSEやMAEがあります。
分類タスク
患者が疾患にかかっているか否か、患者が死亡するか否か、患者が高リスク群に属するか否かなどをグループに属するor属さないを予測するのが分類タスクです。これは分類タスクの中でも二値分類と呼ばれます。①0、1の2種類のラベルで予測をする場合、②0から1の間で確率を予測する場合の2種類が存在します。

このようにグループに属するか否かを2種類のラベル、もしくは0から1の確率で予測するのが分類タスクです。
評価指標として①の場合はF1-score、②の場合はloglossやAUCなどが用いられます。
AUCは医療者の方には馴染みが深いと思います。
また分類タスクには多クラス分類というものも存在します。多クラス分類は二値分類が2つの分類種類が複数になります。
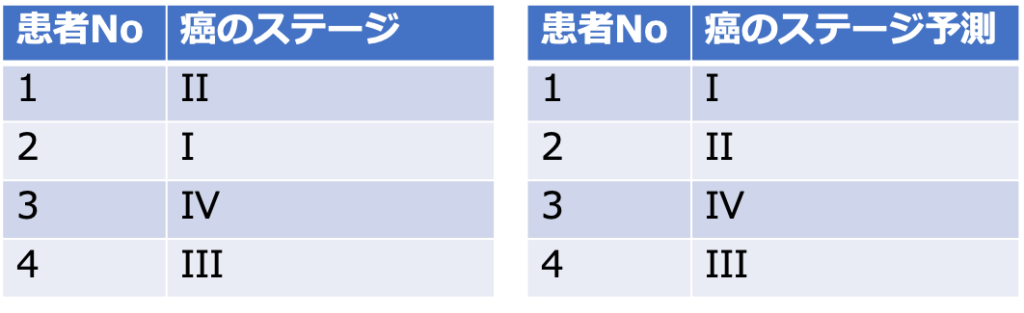
このように予測するものが複数のクラスになった場合の分類タスクを多クラス分類と呼びます。
評価指標としてmulti-class loglossなどが用いられます。
レコメンデーション
レコメンデーションはユーザーが購入しそうな商品やクリックしそうな広告を予測するタスクです。ユーザーが購入しそうな商品を複数個推薦するタスクを想定した場合に、購入する可能性に応じて順位付けをする場合と順位付けをしない場合があります。

評価指標には順位をつけて予測する場合はMAP@Kなどが用いられます。順位をつけない場合はマルチラベル分類と同様のものが用いられます。
さいごに

今回はPythonを用いたデータ分析における3種類のタスクについて勉強しました。
今回の内容をまとめていきます。
Pythonを用いたデータ分析における3種類のタスクは以下のようになっていました。
- 回帰タスク
- 分類タスク
- レコメンデーション
それぞれ内容はこのようになっていました。
- 回帰タスク:株価、医療費、来院数など数値を予測する。
- 分類タスク:グループに属するor属さないを予測する。
- レコメンデーション:ユーザーが購入しそうな商品やクリックしそうな広告を予測する。
それぞれ概念自体の理解はとっつきにくいと思います。
具体例で実際にイメージしながらじっくりと理解していくのが良いと思います。
機械学習はプログラミング言語のPythonを用いれば、今持っている自分のパソコンですぐに実践することができます。
英語論文になっている手法もしっかりと勉強すれば、自分のパソコンで出来ます。
このサイトでは、プログラミングに興味のある医学生、医師のための情報を発信しております。
プログラミングの学習方法には大きく分けて、「独学」と「プログラミングスクール」の2つがあります。
当サイトでは一貫してプログラミングスクールを利用することをおすすめしています。
なぜなら、独学で勉強した私が非常に苦労したからです。
また私はプログラミングを学習するにあたり、師匠・メンターのような存在がいました。
わからないところは教えてもらっていました。
そのような環境でなければ0から独学で勉強するのはとても効率が悪いと思います。
詳しくは、プログラミングの独学は難しいです【私の失敗談】で紹介しています。
この記事が一人でも多くのプログラミングに興味のある方のお役に立てば幸いです。




