
プログラミングに興味がある人「pythonでの機械学習って実際どんなことができるの?」
こんな方に向けた記事です。
実際の機械学習をコード付きで実践します。
最近流行りのAI、機械学習、深層学習。
なんとなく概念は理解したし、少しコードもかけるようになったけど、これが実際に何に役立つのかわからない。
そう思う方も多いと思います。
機械学習は医療分野含め様々な分野で将来性抜群の領域です。
この記事では機械学習で実際に何ができるのか、コード付きで1ステップ毎に解説していきます。
今回はプログラミングコンペkaggleの課題から54個の質問の回答から夫婦が離婚するかどうかを予測するモデルを作成していきます。
Google Colaboratoryを用いてデータ分析を行います。
復習になりますが、Python機械学習でのデータ分析の流れを簡単に表すと次のようになります。
データ分析の流れ
- データの読み込み
- データの把握
- データの前処理
- 機械学習予測モデル作成
- 予測モデルの評価
この流れを意識しながら見てまいりましょう。
目次
【機械学習実践】離婚する夫婦を予測する

まずはkaggleのサイトからデータをダウンロードします。
お示しのようにDownloadをクリックするとデータをダウンロードすることができます。
それでは実際の分析に移って参ります。
1. データの読み込み
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.gridspec as gridspec
import sklearn.model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import metrics
from sklearn.model_selection import KFold
import plotly.graph_objects as go
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
まずはあらかじめ使用しそうなライブラリをインポートしておきます。
これは毎回全て使用するわけではありませんので一つ一つを掘り下げて行く必要はありません。
from google.colab import files
uploaded=files.upload()
これで自身のデスクトップからデータセットを取り込むことが出来ます。
ファイルを選択をクリックしダウンロードしたデータをgoogle colabにインポートします。

このような出力がされればダウンロード完了です。
df=pd.read_csv("divorce_data.csv",delimiter=";")
データのcsvファイルをPandasで読み込みます。今回は各データの区切りが「,」ではなく「;」であったため、delimeter=";"としています。
2. データの把握
df.head()
まずはデータの全貌を把握します。
このデータには54個の質問の回答、そして離婚したかしていないかの結果が記されています。
df
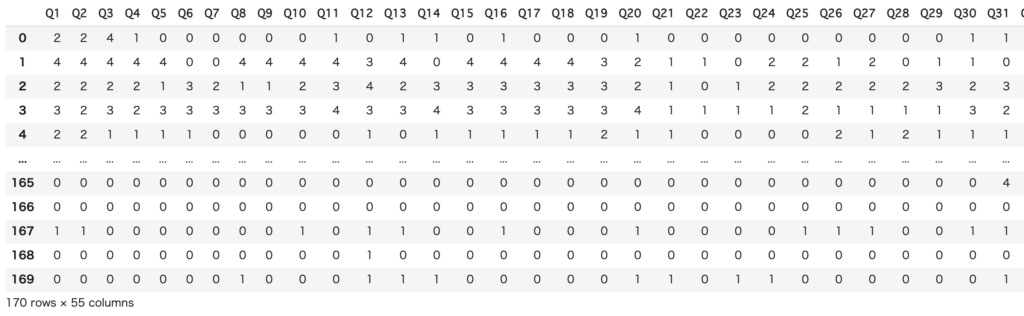
長さの都合上途中で途切れていますがQ54まであります
dfでデータの全貌を表示することができます。本データは54個の質問+離婚の転帰が170人分記されていることがわかりました。
df.describe()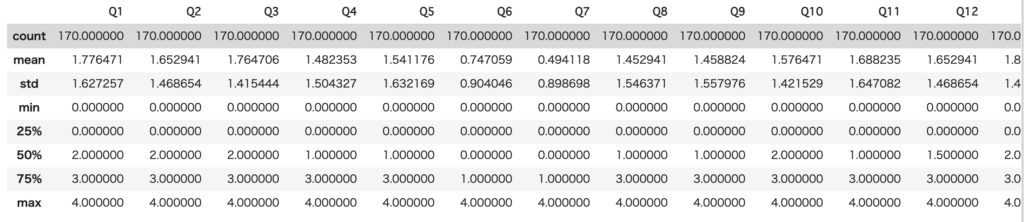
長さの都合上途中で途切れていますがQ54まであります
今回の分析ではあまり意味がありませんが、df.describe()を用いることで最大値、最小値、平均、中央値などを速やかに把握することができます。
df.isna().sum()
長さの都合上途中で途切れていますがQ54まであります
欠損値の有無を把握します。長さの都合上途中までで途切れていますが本データには欠損値はありませんでした。
plt.hist(df["Divorce"])
plt.title("Divorce")
plt.show()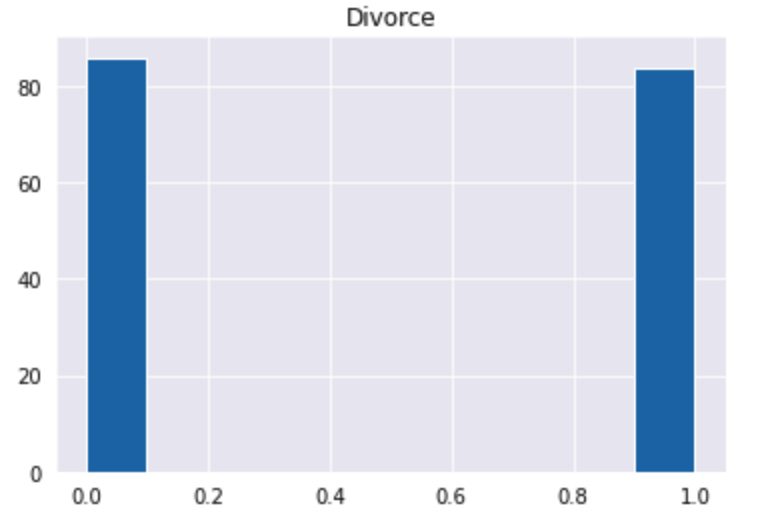
離婚していない(0)と離婚した(1)がどのくらいの比率で存在しているのかを図示して確認します。
今回は2つに大きな数の差はないことがわかります。
3. データの前処理
df_0=df.loc[df["Divorce"]==0]
df_1=df.loc[df["Divorce"]==1]
データの概要を把握した後にデータの前処理を行っていきます。
まず離婚していない人グループ、そして離婚した人グループにグループ分けをします。
今回は離婚していない(Divorce=0)をdf_0、離婚した(Divorce=1)をdf_1とします。


print(len(df_0))
#86print(len(df_1))
#84
それぞれのデータ数を把握することで離婚していない人が86人、離婚した人が84人であることがわかります。


#feature_importanceを推定し可視化する
plt.rcParams["figure.figsize"]=15,6
sns.set_style("darkgrid")
#iloc[index(行), columns(列)] -1は最後の要素
x=df.iloc[:,:-1]
y=df.iloc[:,-1]
model=RandomForestClassifier()
model.fit(x,y)
print(model.feature_importances_)
feat_importances=pd.Series(model.feature_importances_,index=x.columns)
feat_importances.nlargest(10).plot(kind="barh")
plt.show()
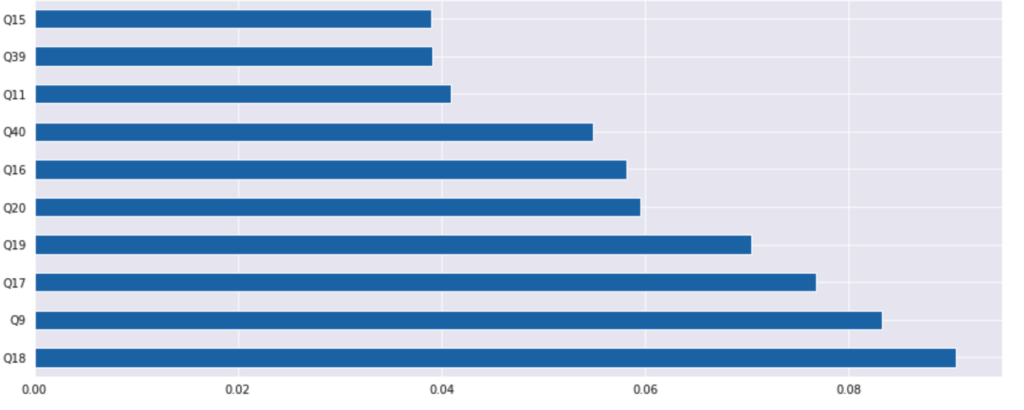
そして特徴量選択を行います。
今回はより影響力のある特徴量上位10個を表示しています。
今回はその中でも上位3つのQ18、Q9、Q17を使用して予測モデルを作成します。
参考までに。
Q18:配偶者と自分の結婚に対するイメージが似ている
Q9:配偶者と旅行に行くのが楽しい
Q17:幸せな生活について同じビジョンを共有している
x=df.iloc[:,[8,16,17]].values
y=df.iloc[:,-1].values
xを上位3質問の回答結果、yを離婚転帰としてグループを作ります。
print(x)
長さの都合上途中で途切れています
print(y)

それぞれ数値だけがグループとなっていることがわかります。
#train_dataとtest_dataにわける
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=0)
ここでデータを訓練用データとテストデータに分割します。今回は全体の20%をテストデータとしました。
sc=StandardScaler() x_train=sc.fit_transform(x_train) x_test=sc.fit_transform(x_test)
標準化を行います。
4. 機械学習予測モデル作成
#logistic regression model
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
model.fit(x_train,y_train)
y_prediction=model.predict(x_test)
from sklearn.metrics import confusion_matrix, accuracy_score
accuracy=accuracy_score(y_test,y_prediction)
print("Accuracy : %s" % "{:%}".format(accuracy))
#混合行列を表示する
cm=confusion_matrix(y_test,y_prediction)
print(cm)
#最後にmodel毎に比較するためにmylistを作成し陳列していく
mylist=[]
mylist.append(accuracy)
まずは線形モデルを作成します。
線形モデルでは94.1%の精度で予測することができました。
#Random forest model #まずn_estimatorsの数を最適化する from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import confusion_matrix, accuracy_score list1=[] for estimators in range(10,30): model=RandomForestClassifier(n_estimators=estimators, criterion="entropy") model.fit(x_train,y_train) y_pred=model.predict(x_test) list1.append(accuracy_score(y_test,y_pred)) #リストを表で可視化する plt.plot(list(range(10,30)),list1) plt.show() #今回は最高のestimatorsの1つであるn=20で施行
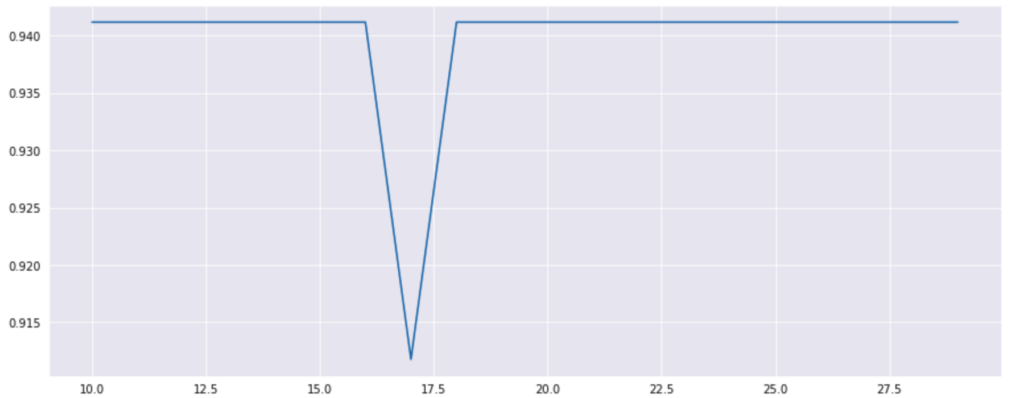
Random Forestモデルを作成します。
まずはRandom Forestのパラメータであるn_estimatorの選択を行います。
今回は良い予測値を出すことができたn=20を使用します。
#Random forest model
#最良のestimotorでRandom forest 施行
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 20, criterion='entropy', random_state=0)
classifier.fit(x_train,y_train)
y_pred=classifier.predict(x_test)
print(y_pred)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test, y_pred)
print(cm)
print(ac)
mylist.append(ac)
ランダムフォレストでも94.1%の精度で予測することができました。
#GBDT Gradient Boosting Decision Tree 勾配ブースティング木 import xgboost as xgb from sklearn.metrics import confusion_matrix, log_loss #特徴量と目的変数をxgboostのデータ構造に変換する dtrain=xgb.DMatrix(x_train,label=y_train) dtest=xgb.DMatrix(x_test,label=y_test) #ハイパーパラメータ―の設定 params={"objective":"binary:logistic", 'eval_metric': 'logloss', 'silent':0} watchlist=[(dtrain,'train')] model=xgb.train(params,dtrain,num_boost_round=100,evals=watchlist) # 学習ラウンド数は適当 y_pred_proba=model.predict(dtest) print(y_pred) # しきい値 0.5 で 0, 1 に丸める y_pred = np.where(y_pred_proba > 0.5, 1, 0) #loglossでは結果が1である確率を検出しているので0.5をカットオフにして0,1を分類する # 精度 (Accuracy) を検証する ac = accuracy_score(y_test, y_pred) print('Accuracy:', ac) mylist.append(ac)

次にGBDTのライブラリであるxgbを使用します。
94.1%の精度で予測することができました。
#xgboost #for 変数 in range([始まりの数値,] 最後の数値[, 増加する量]): from xgboost import XGBClassifier from sklearn.metrics import confusion_matrix, accuracy_score list1 = [] for estimators in range(10,30,1): #for 変数 in range([始まりの数値,] 最後の数値[, 増加する量]): classifier = XGBClassifier(n_estimators = estimators, max_depth=12, subsample=0.7) classifier.fit(x_train, y_train) y_pred = classifier.predict(x_test) list1.append(accuracy_score(y_test,y_pred)) #print(mylist) plt.plot(list(range(10,30,1)), list1) plt.show()
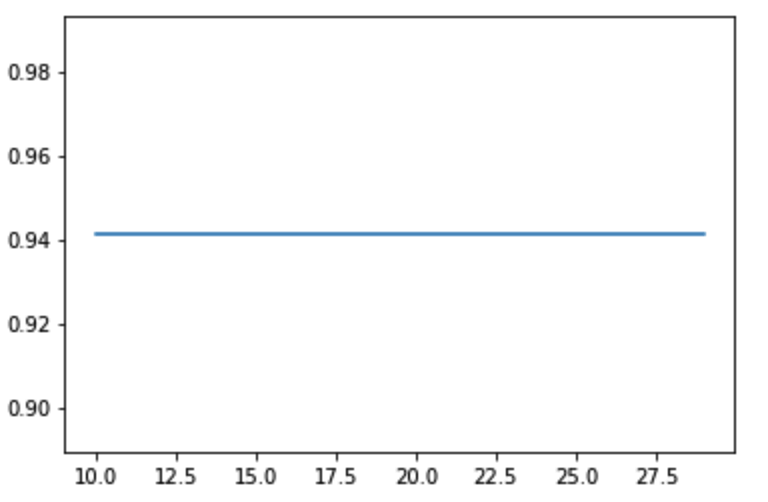
次はGBDTのライブラリであるXGBClassifierを使用します。
まずはパラメータであるn_estimatorの値を探していきます。
今回は10〜30では同じ予測値となりました。
from xgboost import XGBClassifier classifier = XGBClassifier(n_estimators = 10, max_depth=12, subsample=0.7) classifier.fit(x_train,y_train) y_pred = classifier.predict(x_test) print(y_pred) from sklearn.metrics import confusion_matrix, accuracy_score cm = confusion_matrix(y_test, y_pred) ac = accuracy_score(y_test, y_pred) mylist.append(ac) print(cm) print(ac)

今回はn_estimatorを10にして予測を行いました。
94.1%の精度で予測することができました。
5. 予測モデルの評価
mylist
4つのモデルの予測値をそれぞれmylistとして追加していったものを確認します。
今回は4つのモデルで同じ推測値になりました。
mylist2=["Logistic Regression", "RandomForest","xgb","XGBclassifier"]
それぞれの予測値に対するモデルのリストを作成します。
plt.rcParams['figure.figsize']=15,6
sns.set_style("darkgrid")
ax = sns.barplot(x=mylist2, y=mylist, palette = "rocket", saturation =1.5)
plt.xlabel("Classifier Models", fontsize = 20 )
plt.ylabel("% of Accuracy", fontsize = 20)
plt.title("Accuracy of different Classifier Models", fontsize = 20)
plt.xticks(fontsize = 12, horizontalalignment = 'center', rotation = 8)
plt.yticks(fontsize = 13)
#以下の文でbarの上に実際の値を表示している
for p in ax.patches:
width, height = p.get_width(), p.get_height()
x, y = p.get_xy()
ax.annotate(f'{height:.2%}', (x + width/2, y + height*1.02), ha='center', fontsize = 'x-large')
plt.show()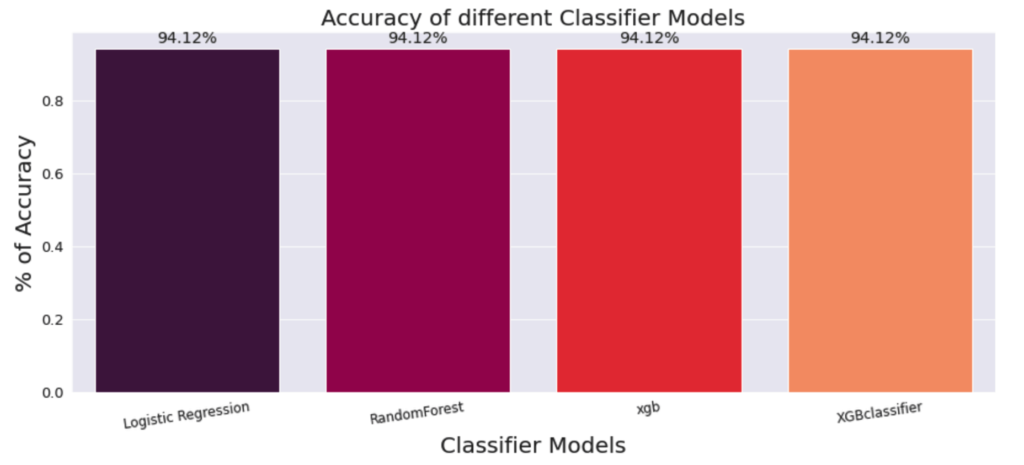
今回作成した4つのモデルの正確性を図示して比較します。
今回は4つのモデルで同じく高い予測値を出すことが出来ました。
さいごに

今回はPython機械学習で夫婦の離婚を予測するモデル構築について一緒に勉強しました。
機械学習はプログラミング言語のPythonを用いれば、今持っている自分のパソコンですぐに実践することができます。
英語論文になっている手法もしっかりと勉強すれば、自分のパソコンで出来ます。
このサイトでは、プログラミングに興味のある医学生、医師のための情報を発信しております。
プログラミングの学習方法には大きく分けて、「独学」と「プログラミングスクール」の2つがあります。
当サイトでは一貫してプログラミングスクールを利用することをおすすめしています。
なぜなら、独学で勉強した私が非常に苦労したからです。
また私はプログラミングを学習するにあたり、師匠・メンターのような存在がいました。
わからないところは教えてもらっていました。
そのような環境でなければ0から独学で勉強するのはとても効率が悪いと思います。
詳しくは、プログラミングの独学は難しいです【私の失敗談】で紹介しています。
この記事が一人でも多くのプログラミングに興味のある方のお役に立てば幸いです。




