
プログラミングを学ぶ人「勾配ブースティング決定木(GBDT)って何だろう?」
こんな方に向けた記事です。
今回はPython機械学習の勾配ブースティング木(GBDT)について一緒に勉強していきましょう。
GBDTを理解する上で必須の決定木の知識、そして決定木を応用したランダムフォレストについては別の記事で紹介しているのでご覧ください。
決定木の記事でも申したようにPython機械学習モデルにはランダムフォレストや勾配ブースティング木など「木」関連のものがよく出てきます。
決定木の考え方さえ理解してしまえば他の「木」関連のモデルの理解は簡単です。基本的に決定木の応用です。
今回紹介するGBDTはPython機械学習の非常に基本的なモデルの一つです。医学論文でもよく用いられています。
それでは早速内容を見てまいりましょう。
本記事の学習目標
- GBDTとは何か理解する。
- GBDTの決定木作成のポイントを理解する。
- GBDTを用いたモデルを理解する。
- GBDTの代表的なパラメーターを理解する。
勾配ブースティング決定木(GBDT)
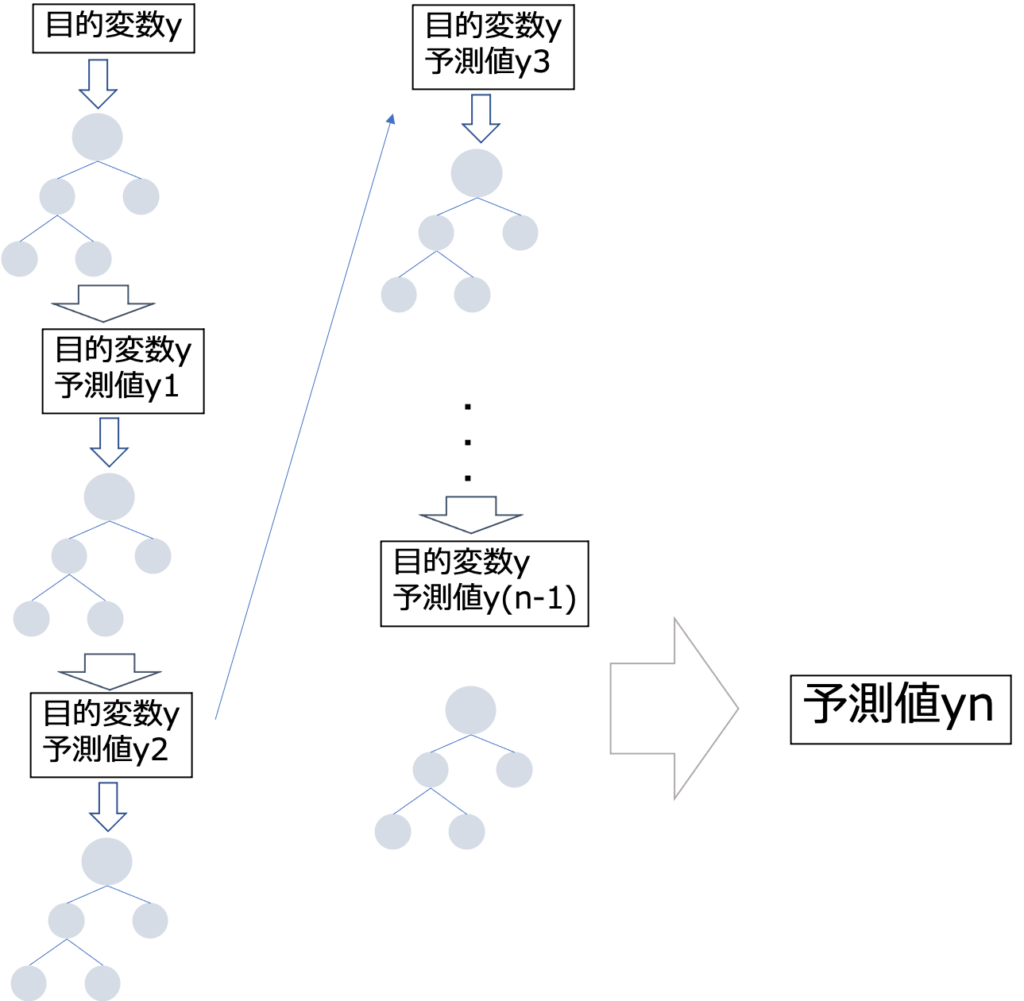
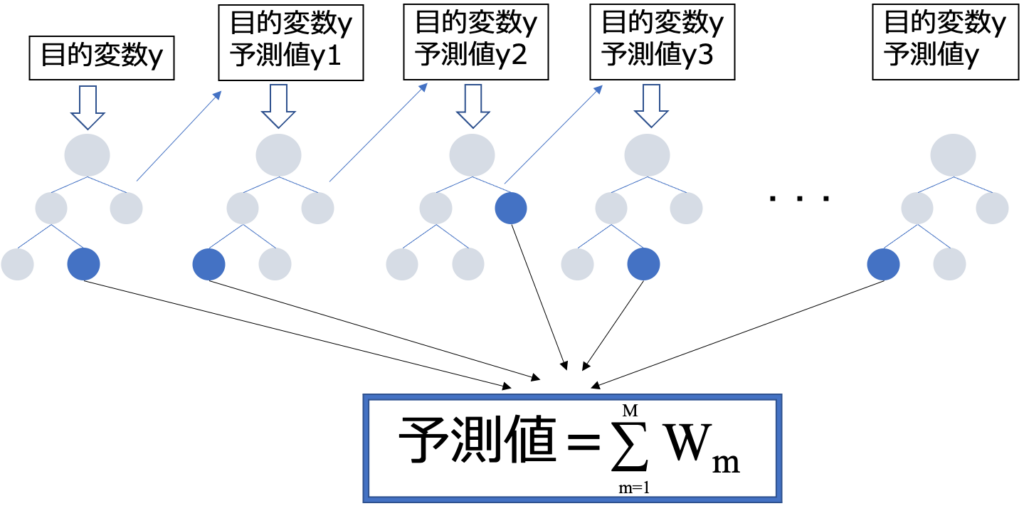
勾配ブースティング決定木の仕組み
- 決定木を作成し予想値を算出する。
- 予測値と目的変数の誤差を算出する。
- 予測値と目的変数の誤差を埋めるように決定木を作成する。
- 指定した決定木の本数繰り返す。
- 予測対象のデータがそれぞれの決定木で属する葉のウェイトの和が予測値となる。
GBDTではこのように決定木を直列に作成し、それまでに作成した予測値に新しい決定木の予測値を加えることによって少しずつ修正していきます。
具体例を考えみましょう。心不全患者の予後を予測するstudyを想定します。患者が「50歳、喫煙歴があるBMI25の男性」である場合を想定してみましょう。
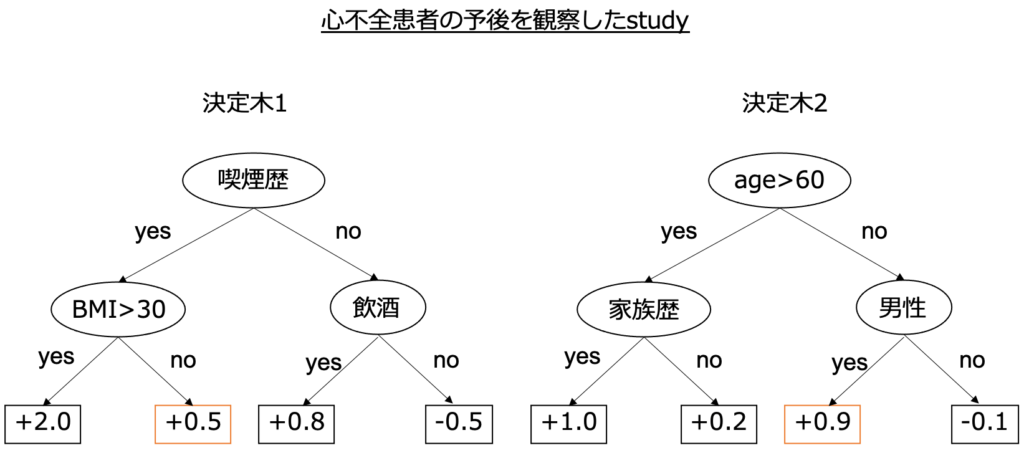
その場合、予測値は0.5+0.9=1.4となります。実際は分類タスクなのでさらにこれを確率に変換し予測確率として出力します。
このように決定木を直列に配置し予測精度を挙げていく手法がGBDTです。
概念がわかったところでGBDTの特徴はどのようなものがあるのか勉強していきましょう。
GBDTの特徴
ここではGBDTの特徴の中でも特に重要な3つの特徴をご紹介します。
GBDTの特徴
- 欠損値を扱うことができる
- パラメータチューニングをしなくとも精度がでやすい
- 不要な特徴量を追加しても精度が落ちにくい
GBDTでは欠損値の場合はあらかじめ分岐でどちらに割り振られるかが決められています。よって欠損値が存在しても問題なくモデルによる解析を行う事ができます。またGBDTはパラメータチューニングをしなくとも精度がでやすく、特徴選択で特徴量を絞らなくとも精度がでやすいと考えられています。
GBDTを用いたモデル
代表的なGBDTを用いたライブラリには以下の3つがあります。
GBDTを用いたライブラリ
- xgboost
- lightgbm
- catboost
医学論文では多くの場合は現在のところxgboostが使われています。
3つの違いについて現時点で詳細に理解する必要はあまりないと思います。違いが気になる方はこちらのlogmiTechさんの記事で非常にわかりやすく解説されているのでぜひ参考にしてみてください。
GBDTのパラメータ
GBDT(xgboost)のパラメータには以下のようなものがあります。
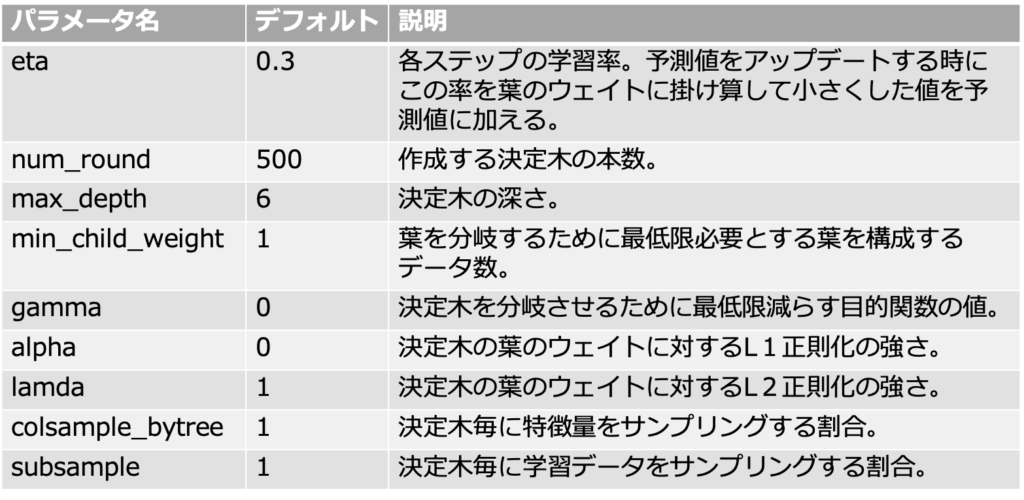
Xgboostは先述のようにパラメータチューニングをせずともある程度高い予測精度を期待する事ができます。
xgboostのパラメータチューニングについてはxgboost公式サイトで詳細に説明されていますので気になる方は是非御覧ください。
さいごに

概念自体の理解はとっつきにくいと思います。
具体例で実際にイメージしながらじっくりと理解していくのが良いと思います。
機械学習はプログラミング言語のPythonを用いれば、今持っている自分のパソコンですぐに実践することができます。
英語論文になっている手法もしっかりと勉強すれば、自分のパソコンで出来ます。
このサイトでは、プログラミングに興味のある医学生、医師のための情報を発信しております。
プログラミングの学習方法には大きく分けて、「独学」と「プログラミングスクール」の2つがあります。
当サイトでは一貫してプログラミングスクールを利用することをおすすめしています。
なぜなら、独学で勉強した私が非常に苦労したからです。
また私はプログラミングを学習するにあたり、師匠・メンターのような存在がいました。
わからないところは教えてもらっていました。
そのような環境でなければ0から独学で勉強するのはとても効率が悪いと思います。
詳しくは、プログラミングの独学は難しいです【私の失敗談】で紹介しています。
この記事が一人でも多くのプログラミングに興味のある方のお役に立てば幸いです。




