
プログラミングを学ぶ人「ランダムフォレストって何だろう?」
こんな方に向けた記事です。
今回はPython機械学習のランダムフォレストについて一緒に勉強していきましょう。
ランダムフォレストを理解する際に必ず理解する必要がある決定木の考え方についてこちらの記事で紹介しています。まだご覧になっていない方は一度目を通して見てください。
決定木の記事でも申したようにPython機械学習モデルにはランダムフォレストや勾配ブースティング木など「木」関連のものがよく出てきます。
決定木の考え方さえ理解してしまえば他の「木」関連のモデルの理解は簡単です。基本的に決定木の応用です。
今回紹介するランダムフォレストはPython機械学習の非常に基本的なモデルの一つです。医学論文でもよく用いられています。
それでは早速内容を見てまいりましょう。
本記事の学習目標
- ランダムフォレストとは何か理解する。
- ランダムフォレストの決定木作成のポイントを理解する。
- ランダムフォレストを用いたモデルの特徴を理解する。
- ランダムフォレストの代表的なパラメーターを理解する。
【機械学習】ランダムフォレストをわかりやすく解説
ランダムフォレストは一言で言うと決定木の集合により予測を行うモデルです。
特徴は決定木を並列に作成する点です。それぞれの特徴量をサンプリングして付与することで多くの決定木を作成しこれらを組み合わせることで高精度の予測をすることが出来ます。
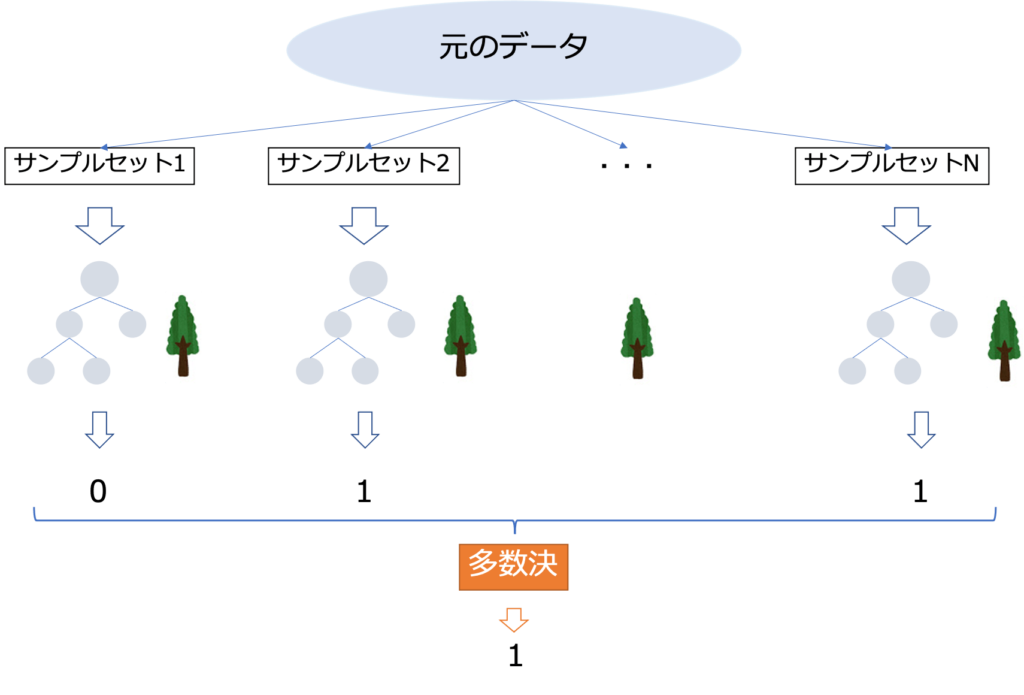
ランダムフォレストの仕組み
- 元データをN個のサンプルセットに分割する。
- N個のグループそれぞれで決定木モデルを作成する。
- N個のグループそれぞれのモデルで予測を行う。
- N個の予測結果から多数決で最終予測を行う。
これがランダムフォレストです。
まず元データをN個のサンプルデットに分割、そしてそれぞれで決定木モデルによる予測を行います。この決定木モデル結果の多数決で予測結果を出力します。
ランダムフォレストの決定木作成は、回帰タスクでは二乗誤差、分類タスクではジニ係数が最も減少するように行われます。
分岐ごとに特徴量の一部をサンプリングしたものを候補として、その中から分岐の特徴量が選択されます。
決定木を並列に作成するため、ある程度増やすと精度が上がらなくなってきます。決定木の本数は計算時間と精度のトレードオフで定められます。
予測確率の妥当性はランダムフォレストではジニ係数を最小化しようとする各決定木の予測を平均することで行われます。
ランダムフォレストのパラメータ
前提としてランダムフォレストではパラメータチューニングをしなくとも比較的良い精度が算出されます。ですので予測はデフォルト設定でほとんど事足ります。
今回は重要なパラメータ2つを紹介します。
ランダムフォレストの代表的なパラメータ
- n_estimators
- max_features
n_estimators
元のデータをいくつに分割するかを指定します。今回の表におけるサンプルセットNのNを指定するのがこのn_estimatorsです。
理論的には大きければ大きい程精度が上がります。10人に多数決をとるよりも1000人に多数決をとった方がより精度が高い結果になりますよね。
しかし、分割数を上げれば上げるほど計算に時間がかかります。この精度と計算時間のバランスを考慮する必要があります。
max_features
先述のようにランダムフォレストでは分岐ごとに特徴量の一部が抽出されています。つまり、各サンプルデータごとに決定木で用いられる特徴量がランダムに割り振られているということです。
この各サンプルデータ毎に割り当てられる特徴量の数を指定するのがmax_featuresです。
max_featuresが大きいと各決定木モデルは同じようなモデルになります。一方でmax_featuresが小さい、極端に言うと1であるとそれぞれの決定木モデルは全く異なるものになります。
さいごに

今回はPython機械学習の基本的なモデルの一つであるランダムフォレストについて一緒に勉強しました。
ランダムフォレストは並列の決定木モデルの多数決により予測するPythonの機械学習モデルでした。
ランダムフォレストの決定木作成は回帰タスクでは二乗誤差、分類タスクではジニ係数が最も減少するよう作成されています。
ランダムフォレストの代表的なパラメータにはn_estimators、max_featuresが挙げられます。
n_estimatorsは元のデータをいくつに分割するかを指定する、そしてmax_featuresは各サンプルセット毎に割り当てられる特徴量の数を指定するものでした。
概念自体の理解はとっつきにくいと思います。
具体例で実際にイメージしながらじっくりと理解していくのが良いと思います。
機械学習はプログラミング言語のPythonを用いれば、今持っている自分のパソコンですぐに実践することができます。
英語論文になっている手法もしっかりと勉強すれば、自分のパソコンで出来ます。
このサイトでは、プログラミングに興味のある医学生、医師のための情報を発信しております。
プログラミングの学習方法には大きく分けて、「独学」と「プログラミングスクール」の2つがあります。
当サイトでは一貫してプログラミングスクールを利用することをおすすめしています。
なぜなら、独学で勉強した私が非常に苦労したからです。
また私はプログラミングを学習するにあたり、師匠・メンターのような存在がいました。
わからないところは教えてもらっていました。
そのような環境でなければ0から独学で勉強するのはとても効率が悪いと思います。
詳しくは、プログラミングの独学は難しいです【私の失敗談】で紹介しています。
この記事が一人でも多くのプログラミングに興味のある方のお役に立てば幸いです。




